Mark Data Model
Mark extends JSON with additional data types and introduces the Mark element concept.
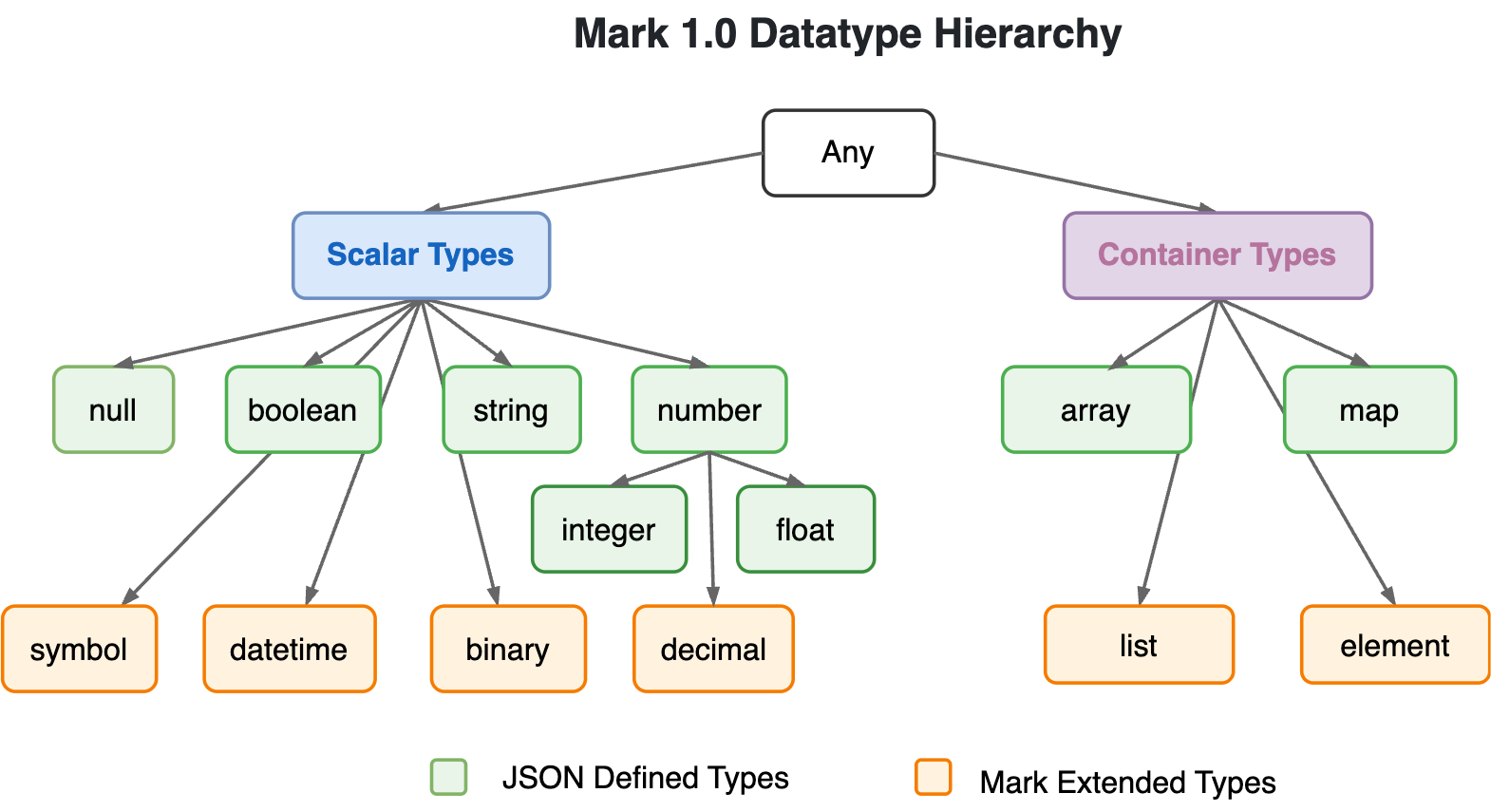
Datatype Hierarchy
Mark adds a few new data types to JSON: symbol, datetime, binary, list and element, well covering all the commonly used built-in datatypes in JS.
Element
Mark element = name + map + array.
It maps to just one plain JavaScript object, containing both named and indexed properties. Much more compact and efficient than other
JSON-based DOM models.